
Наконец-то вскрылись архивы ещё одной особо ценной конференции 2025 года. Издательство Всероссийского научно-исследовательского института экспериментальной физики выпустило сборник тезисов XXVI Харитоновских тематических научных чтений «Искусственный интеллект и большие данные в технических, промышленных, природных и социальных системах». Чтения прошли 14–18 апреля в Сарове, что само по себе создавало некий флёр секретности, тайны — притом, что любой желающий мог запросто подключиться к онлайн-трансляции и насладиться междисциплинарным диалогом около двухсот ИИ-специалистов.
Среди них обнаружилось целых семь спикеров от Института проблем искусственного интеллекта. И неудивительно, ведь институты давно сотрудничают в рамках одноимённого проекта № 9 (ссылка) по направлению 9.3 «Разработка и исследование технологий искусственного интеллекта для профилактической медицины, психодиагностики и биометрии». Открывал конференцию лично Олег Григорьев. Он презентовал коллективный труд нескольких отделов «Технологии искусственного интеллекта в профилактической медицине» (ссылка), а конкретно базу знаний системы здоровьесбережения.
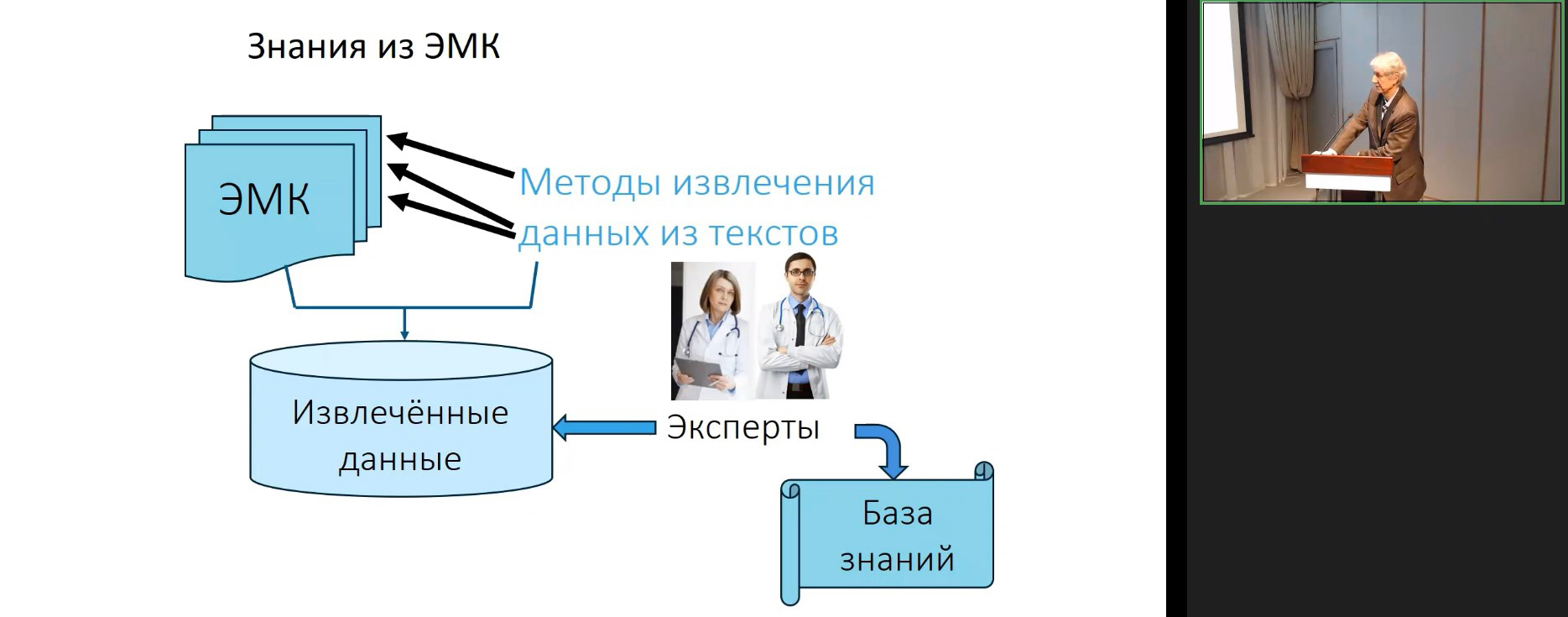
БЗ собирают с помощью экспертов, менеджер здоровья оценивает риски заболеваний. А знания о заболеваниях, факторах риска, причинах, возможных осложнениях и профилактике извлекают из полных текстов статей, исследований, отчётов, экспертных мнений и, сверх того, из массивов с разнородными данными. Система объединяет и интегрирует различные технологии ИИ, что позволяет отслеживать выполнение рекомендаций и оценивать состояние здоровья в динамике. Собственно, обзору технологий и были посвящены остальные доклады.
Например, Иван Смирнов рассказал о своём многопрофильном коллективе и выявлении психологического неблагополучия путём обработки естественного языка. «Технологии психолингвистического анализа текстов для здоровьесбережения» (ссылка) помогают выявлять и оценивать расстройства, депрессивность, тревожность, отношение к ЗОЖ сотрудников предприятий или даже жителей моногородов исходя из их текстов в социальных сетях, корпоративной переписки, массового анкетирования. Одновременно можно измерять смену настроений целых сетевых сообществ, их психоэмоциональную реакцию на те или иные события, страхи и предрассудки.
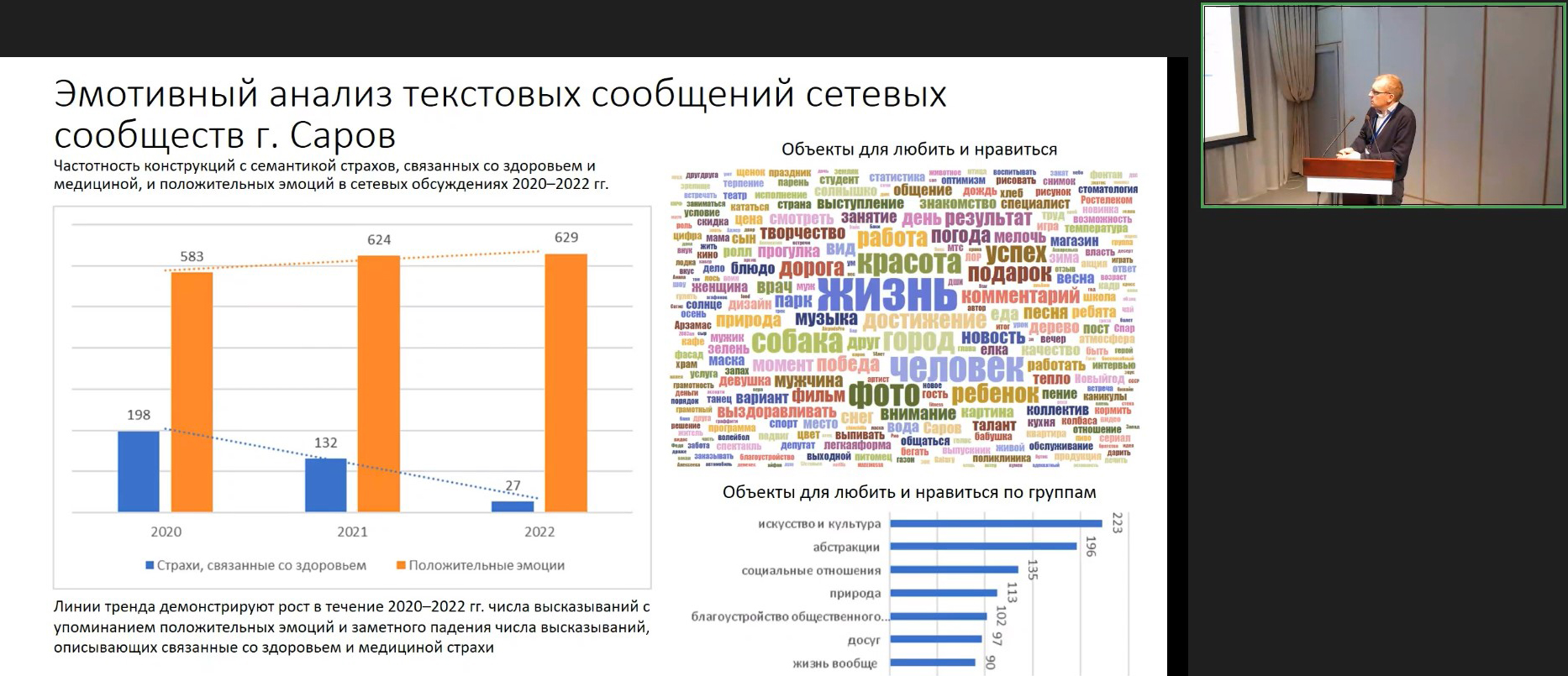
В качестве примеров Иван привёл результаты исследования пабликов Сарова, в частности, динамику социального напряжения, панических настроений, упоминания властей и просто неоднозначную реакций сообществ на эпидемию COVID-19 и самоизоляцию.
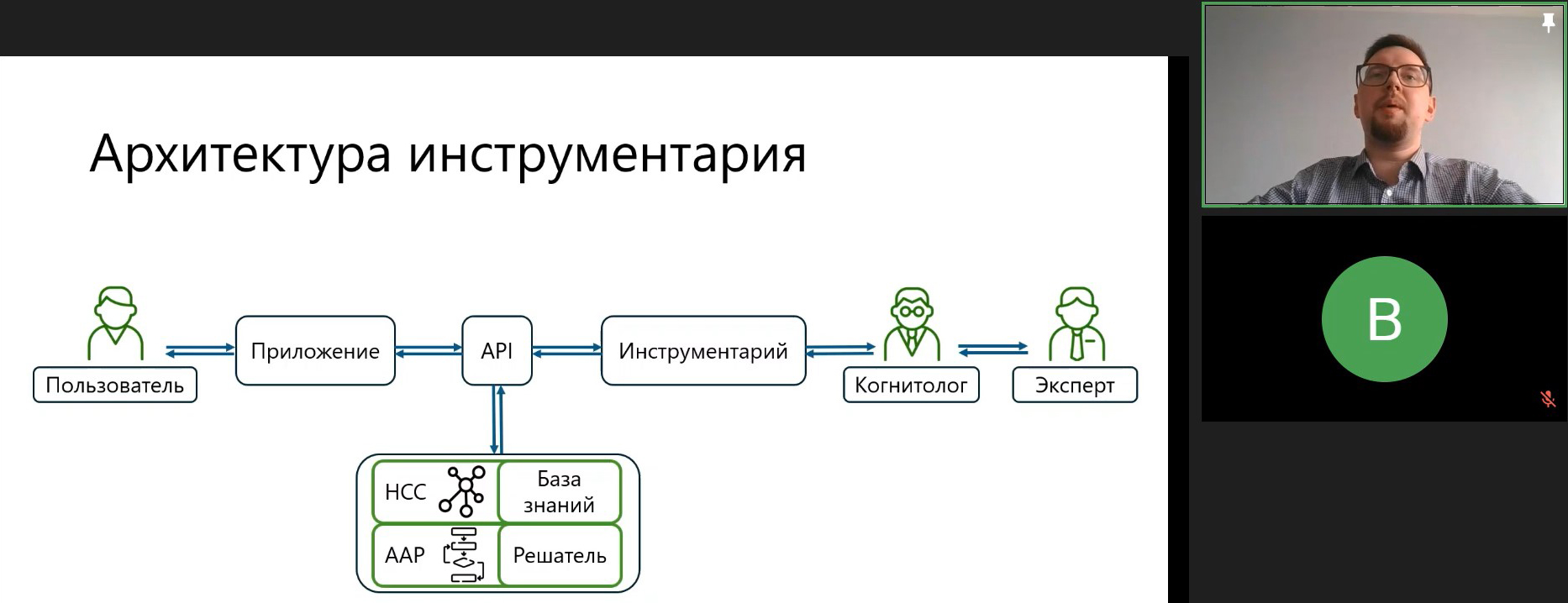
Сменивший его Николай Благосклонов (при незримой поддержке Артёма Николаева и Андрея Пальчевского) представил «Инструментарий для формирования базы знаний и решателя интеллектуальной медицинской системы» (ссылка). А именно БЗ на основе неоднородной семантической сети, состоящую из разделов, четырёх вариантов узлов, их свойств и связей между ними. Логический вывод же реализовали за счёт алгоритма аргументационных рассуждений, который включает 9 шагов. Причём для расширения диапазона решаемых задач была добавлена возможность отключать шаги 7–9, что нашло применение в чудесной ИИ-ГИППОКРАТ.
Борис Аркадьевич Кобринский подхватил инициативу и дал обоснование «Системе искусственного интеллекта для мониторинга риска хронических болезней» (ссылка). Модель анализирует динамику переходных состояний организма и позволяет использовать цифровой двойник человека для оценки потенциальных возможностей возврата системы к предыдущему фазовому состоянию, дабы контролировать воздействие протекторов (профилактических мер) на управляемые факторы риска. В ней переходные процессы демонстрируют общность фазовых переходов и критического явления, например, гипертонический криз как следствие артериальной гипертонии.

А Дмитрия Девяткина заинтересовали «Методы и технологии поиска в больших массивах биомедицинских и биохимических текстов» (ссылка). Задача непростая, прежде всего из-за разнородности данных, когда часть сущностей представлена в структурированном виде, а часть — текстовыми описаниями. Современным подходам не хватает точности, поэтому команда придумала свой метод построения единого поискового индекса и связей между сущностями, а на его фундаменте построила систему биохимического и биомедицинского поиска.
Демонстрационная система включает в себя модули извлечения информации из текстов и обработки данных о химических соединениях, инвертированный семантический индекс и хранилище структурных (графовых) представлений химических соединений. Похожая система уже была реализована и описана в статье о «кросс-языковых эмбеддингах для извлечения химических структур из текстов на русском и английском языках» (ссылка) для журнала INJOIT — подробнее читайте в майских новостях. Результаты испытаний почти неотличимы от «золотого стандарта», коммерческой платформы CAS SciFinder, что стало приятным сюрпризом для всех.

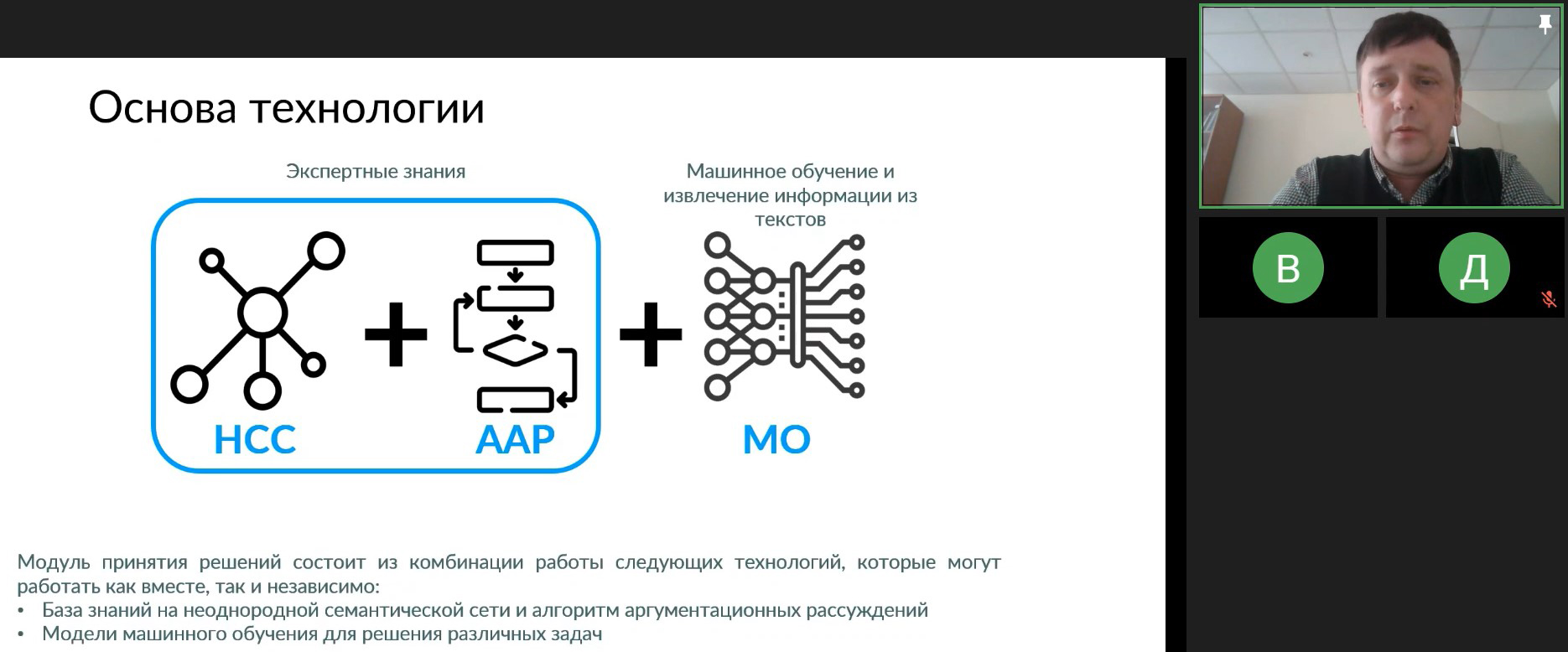
Наконец, Алексей Молодченков и Антон Лукин в презентации «Извлечение знаний из различных источников и технология сбора данных пациентов» (ссылка) поделились историей о том, как обучали БЗ. Ещё Геннадий Осипов предложил строить базу с помощью экспертов, когда в качестве способа представления знаний выступает неоднородная семантическая сеть. Однако это отнимало слишком много времени, что вынудило создать новый подход для обучения серии агентов, которые автоматически строят базу на основе обработки большого количества текстов. Каждый агент решает свою задачу, а эксперт лишь корректирует результаты. В итоге примерно за 10 часов удалось построить более 2,4 тысяч связей, точность подхода составила 88%, а заодно были выявлены и скорректированы ошибки самого эксперта.
Выступление Максима Станкевича пришлось на другой день и даже другую, молодёжную, секцию, что не делало его менее релевантным. Он рассказал об «Оценке ментального здоровья человека с помощью методов искусственного интеллекта» (ссылка) — интеллектуального анализа данных, обработки естественного языка и машинного обучения, в частности, на примере данных с Cross-Language Evaluation Forum 2018. Два исследования Максим с командой 72 отдела ФИЦ ИУ РАН посвятили решению задач выявления депрессии (ссылка) и личностных черт (ссылка) по цифровым следам из VK, и ещё одно — выявлению депрессии по тексту эссе человека клиническим способом (ссылка). Для чего пришлось прибегнуть к трём поколениям методов обработки естественного языка и богатству инструментария TITANIS.
Cсылки по теме: