
Как вы помните, в апреле мы сообщали о труде коллектива Института проблем искусственного интеллекта для журнала «Жанры речи» под названием «Большие языковые модели и жанрово-речевая системность» (ссылка), для которого пришлось провести комплексное исследование задачи идентификации речевых жанров в научных текстах, прибегнув к услугам трансформера. Так вот, Дмитрий Девяткин, Алексей Молодченков и Антон Лукин совместно с коллегами из РУДН и Института биомедицинской химии решили идти дальше и препарировать биохимические тексты!
В свежем выпуске International Journal of Open Information Technologies Лаборатории открытых информационных технологий факультета ВМК МГУ появилось развёрнутое описание их нового алгоритма для внедрения кросс-языковых эмбеддингов для извлечения химических структур из текстов сразу на русском и английском языках: Development of Cross-Language Embeddings for Extracting Chemical Structures from Texts in Russian and English (ссылка). Мозг алгоритма составили два блока: блок текстовых аннотаций и блок настройки предварительно обученных моделей на основе всё той же трансформенной архитектуры — mBERT и LaBSE.
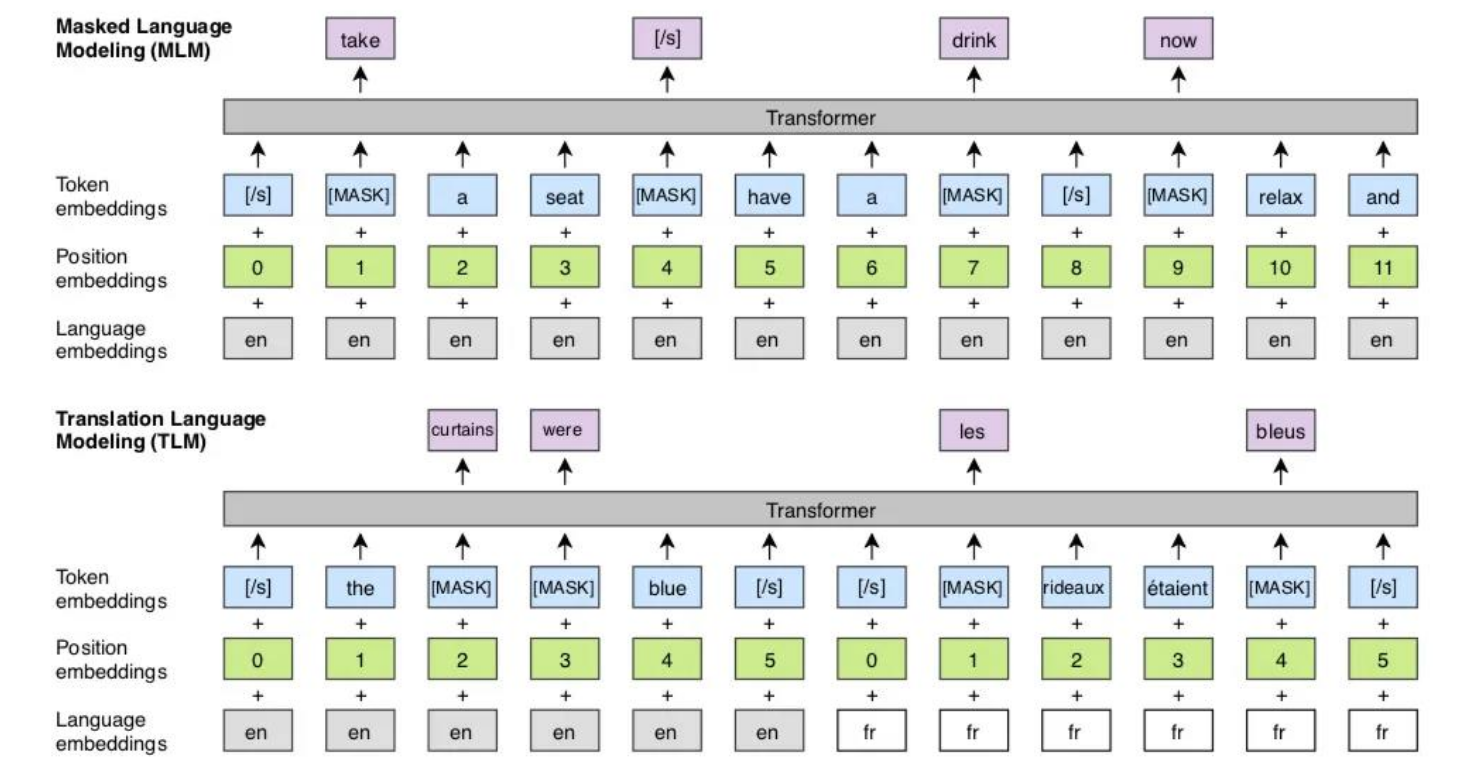
Для поиска текстов в различных научных датабазах авторы использовали нашу любимую цифровую платформу SciApp. Охват датасетов простёрся на все области химии, биохимии, кристаллографии и т. п. Настраивали БЯМы при помощи огромной стопки русско- и англоязычных статей и патентов (для чего пришлось обзавестись корпусом ChemProt). Ну а с обучением моделей помогали задачи маскированного языкового моделирования (MLM) и распознавания именованных сущностей (NER). После чего результаты сравнили с аналогичными результатами от BERT, BioBERT и ChemBERTa. И не в пользу последних, поскольку команде реактивных химиков удалось существенно улучшить показатели.
Подробнее об эксперименте вы можете прочитать на сайте издателя. Правда, текст публикации, в отличие от предмета исследования, ограничился лишь английским наречием. Впрочем, сами учёные презентовали алгоритм и на родном языке, но произошло это совсем в другом месте и в другое время, о чём мы напишем чуть позже. Следите за новостями!
Cсылки по теме: