25 сентября в Санкт-Петербурге состоялось открытие 7-й Международой научой конференции «Интеллектуальные информационные технологии в технике и на производстве» IITI’23. Сотрудники Института проблем искусственного интеллекта и Российской ассоциации искусственного интеллекта — завсегдатаи конференции, и в этот раз их в едином лице представлял Александр Панов. Он спецрейсом вылетел в культурную столицу, чтобы вместе с профессором Института компьютерных наук и технологий Львом Уткиным открыть первую рабочую секцию «Машинное обучение и его применение» как модератор и докладчик.

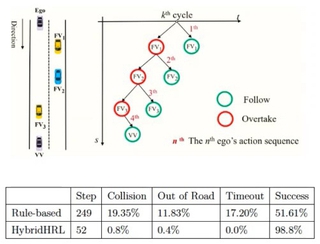
В рамках форума он рассказал о планировании манёвров беспилотного транспорта на основе обучения с подкреплением не в онлайне, а на отложенных данных (ссылка), и, прежде всего, о самом подходе, когда агенту заранее не известны ни цель, ни т. н. вознаграждения, ни реакции среды, а обучение ведётся автономно, с использованием накопленных данных из различных источников. Подход заявлен как более дешёвый (более быстрый) по сравнению с системами на основе правил.
Александр затем продемонстрировал поражённой аудитории беспилотный автомобиль Я САМ, на котором команда «обкатывает» задания, его трёхуровневую архитектуру управления и планировщики манёвров.
В заключение был разобран метод Conservative Q-Learning, параметры его регулирования и тестовые сценарии одного из крупнейших датасетов CommonRoad. Апогеем стали сравнительные таблицы пяти ключевых методов с разбивкой по сценариям («левый поворот», «правый поворот», «вперёд»), качеству генерируемых траекторий (низкое, среднее и высокое), вознаграждениям и показателям успеха. Результаты почти не отличались от результатов тестирований «в онлайне», однако адаптивность подхода к изменяющимся условиям и устойчивость к сложным сценариям развязывают авторам руки для новых и новых испытаний.
А во второй половине дня уже в Москве выступил Алексей Скрынник с анонсированной ранее лекцией «Исследование и разработка методов обучения с подкреплением для задач навигации в визуальных и клеточных средах» (ссылка). Да, и вновь обучение с подкреплением, причём особый акцент докладчик сделал не на многоагентности как одном из ключевых факторов централизованного планирования. Напротив, он обратился к методам, позволяющим роботам действовать автономно в стохастических средах, а также симулятору для тестирования сценариев как одноагентных, так и многоагентных задач навигации. Общей целью была оптимизация стратегии для максимизации суммарного вознаграждения за взаимодействие со средой в течение длительного количества эпизодов.
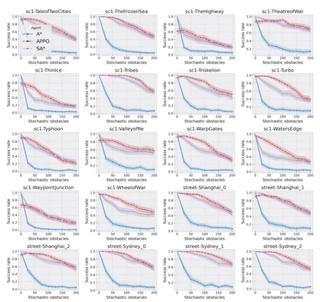
В первом эксперименте действие перенесли в клеточную среду POGEMA с видом сверху, ограничили бедного робота четырьмя направлениями движения и заставили прокладывать себе путь при частичной наблюдаемости, хаотично возникающих преградах, в окружении других агентов при отсутствии коммуникации между ними. Не говоря уже о шансе навеки застрять в колебательном цикле. В помощь были брошены два подхода: планирование с учётом истории наблюдений и дополнительных модификаций (обнаружение случайных препятствий и выполнение «жадных действий»), а также обучение на данных карт улиц Москвы, лабиринтов-головоломок и двух многопользовательских видеоигр. В итоге распределённый подход на основе архитектуры «Актор-Критик» по всем картам дал хороший результат, и обучаемый агент APPO адаптировался намного лучше базового A* и улучшенного SA*.
Следующий этап исследования протекал в трёхмерной среде видеоигры Minecraft (вид из глаз). Робот, заточённый в сложном процедурно генерируемом открытом мире, был вынужден решать множественные задачи навигации (ориентация в пространстве, повороты камеры) и использования предметов на пути к заветной цели: добыче алмаза! Справиться с квестом помог алгоритм забывания ForgER. Благодаря ему после обучения в т. н. фазе имитации агент, попадая в среду, постепенно уменьшал зависимость своей стратегии от экспертных данных и параллельно использовал данные из других подзадач. Авторский подход ForgER одним из первых завоевал алмаз и мировое признание, а соперникам впоследствии пришлось изрядно попотеть, чтобы превзойти его.

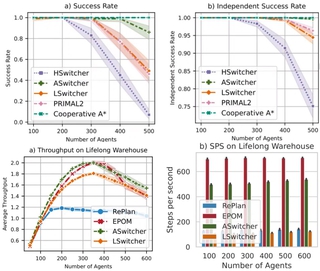
Ещё одним решением стала интеграция методов планирования и обучения с подкреплением в задачах многоагентной навигации, также при участии POGEMA в условиях, аналогичных проблеме однородных сред. Предложенный подход, в целом повторяя её архитектуру, привнёс две модификации: модуль Grid Memory с возможностью запоминать и переиспользовать карту с препятствиями, и популяционное обучение — настройку гиперпараметров в онлайн-режиме, с сохранением только лучших стратегий. А для переключения между обучаемыми и планировочными методами был разработан алгоритм Switcher и варианты переключения: эвристический, ассистивный и обучаемый. ASwitcher, лучший из трёх, показал результаты, превосходящие текущие классические и обучаемые методы на множестве тестовых заданий.
Все алгоритмы уже активно применяются и ещё сыграют заметную роль в задачах робототехники, логистики и, между прочим, беспилотной навигации. Да, Александр Панов зримо и незримо присутствовал на лекции, уделив время в промежутке между сессиями. И не мудрено, ведь он — не только начальник, но и научный руководитель Алексея. Пользуясь случаем, желаем всяческих успехов в защите диссертации!
Cсылки по теме: